PyBrain is stands for Python-Based Reinforcement Learning, Artificial Intelligence, and Neural Network Library is knows as PyBrain. Pybrain is an open source and machine learning library. It is flexible, easy-to-use yet still powerful algorithms for Machine Learning. Some easy to use training algorithms for networks, datasets, trainers to train and test the network.
Features of Pybrain
There are some the features of Pybrain are following :-
Networks
A network is compose of modules. They are connect using connections. Pybrain supports neural networks just like Recurrent Network, Feed-Forward Network, etc
Feed-forward network
It is a neural network, where information between nodes moves in forward direction and will never travel backward. Feed Forward network is first and simplest one among the networks available in artificial neural network.
The information is passes from input nodes, next to hidden nodes and later to output node.
Recurrent Networks
It is are similar to Feed Forward Network and the only difference is that it has to remember data at each step. The history of each step has to be save.
Datasets
Datasets is the data to be given to validate, test or train on networks. The type of dataset to be use depends on the tasks that we are going to do with Machine Learning. The most commonly use datasets that Pybrain supports are two DataSet.
- SupervisedDataSet.
- ClassificationDataSet.
SupervisedDataSet
It is consists of fields of target or Input. It is the simplest form of a dataset and mainly use for supervise learning tasks.
ClassificationDataSet
It is mainly use to deal with classification problems. It takes in target field, Input field or also an extra field called “class” which is an automatic backup of the targets given.
Trainer
When we create a network, it will get train based on the training data given to it. Now whether the network is train properly or not will depend on the prediction of test data test on that network.
BackpropTrainer
It is a trainer that trains the parameters of a module according to a supervise or ClassificationDataSet dataset by backpropagating the errors.
TrainUntilConvergence
It is use to train the module on the dataset until it converges.
Tools
Pybrain offers tools modules which can help to build a network by importing
package : pybrain.tools.shortcuts.buildNetwork
Visualization
The testing data cannot be visualize using pybrain. But Pybrain can work with other frameworks just like Mathplotlib, pyplot to visualize the data.
Advantages of Pybrain
- Pybrain is an open source free library to learn Machine Learning.
- It is uses python to implement it and it fast in development in comparison to languages.
- Pybrain works easily with other libraries of python.
- Pybrain offers support for popular networks like Feed-Forward Network, Recurrent Networks, etc.
- Working with .csv to load datasets is very easy in Pybrain.
- Training and testing of data are easy.
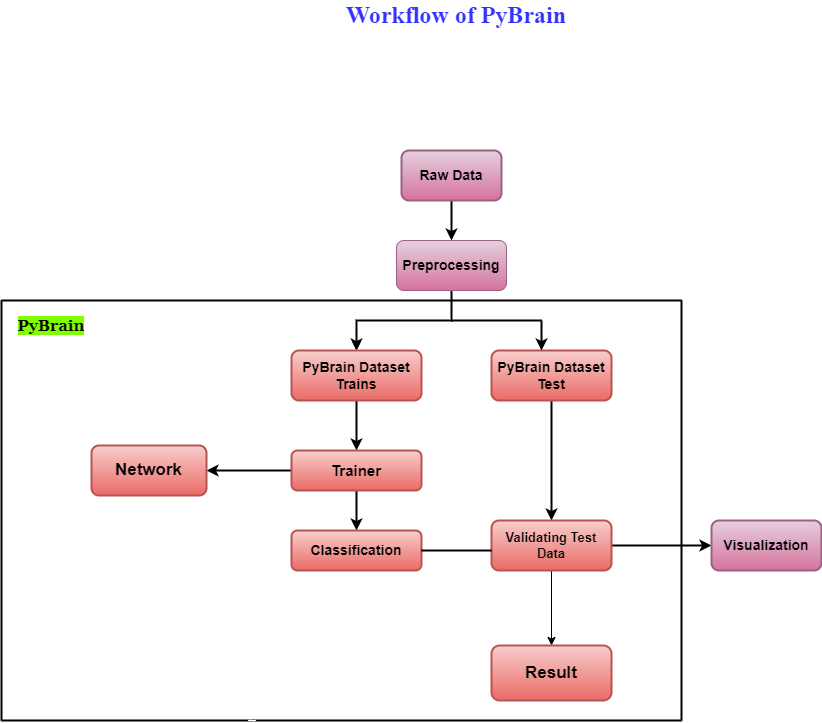
Workflow of PyBrain
- First we have raw data, then after pre-processing, the data can be use by the Pybrain library.
- The major flow of the Pybrain library begins when the dataset is divide into train and test datasets.
- After the division of datasets, the network gets create and the network and dataset are hand over to the trainer.
- The model is trained by the trainer on the network and then the classification of the output is done as the trainer error and validation error. After this classification the error is visualize.
- The test data is validate to make sure the output matches the train data.
DATASET CREATION
Dataset package is use to create a dataset using Pybrain.
A supervise dataset needs two things:-
- Input
- Target
Example of Dataset creation
From pybrain.datasets import SupervisedDataSet Create_data = SupervisedDataSet(5, 2) Print(Create_data)
Output of Dataset creation
Input: dim(0,5) []
Target: dim(0,2) []
PUTTING DATA TO DATASET
Example of Putting data
from pybrain.datasets import SupervisedDataset create_dataset = SupervisedDataSet(2, 1) Model_Xor = [ [(0, 0), (0, )], [(0, 1), (1, )], [(1, 0), (1, )], [(1, 1), (0, )], ] For input, target in Model_Xor: Create_dataset.addSample(input, target) print(“Input is below: ”) print(sds[‘input’]) print(“\nTarget is as follows: ”) print(sds[‘target’])
Output of putting data
Target is as follows:
[[ 0. 0.]
[0. 1.]
[1. 0.]
[1. 1.]]Input is below:
[[ 0. 0.]
[0. 1.]
[1. 0.]
[1. 1.]]SupervisedDataSet
SupervisedDataSet is the simplest form of a dataset and mainly use for supervise learning tasks.
import
from pybrain.datasets import SupervisedDataSet
Example of SupervisedDataset
from pybrain.tools.shortcuts import buildNetwork from pybrain.structure import TanhLayer from pybrain.datasets import SupervisedDataSet from pybrain.supervised.trainers import BackpropTrainer nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer) norgate = SupervisedDataSet(2, 1) nortrain = SupervisedDataSet(2, 1) norgate.addSample((0, 0), (1,)) norgate.addSample((0, 1), (0,)) norgate.addSample((1, 0), (0,)) norgate.addSample((1, 1), (0,)) nortrain.addSample((0, 0), (1,)) nortrain.addSample((0, 1), (0,)) nortrain.addSample((1, 0), (0,)) nortrain.addSample((1, 1), (0,)) trainer = BackpropTrainer(nn, norgate) for epoch in range(1000): trainer.train() trainer.testOnData(dataset=nortrain, verbose = True)
Output of SupervisedDataset
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218, 0.005227359234093431
, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)
ClassificationDataSet
ClassificationDataSet is mainly use to deal with classification problems.
Syntax of ClassificationDataSet
ClassificationDataSet(inp, target=1, nb_classes=0, class_labels=None)
Import of ClassificationDataSet
from pybrain.datasets import ClassificationDataSet
Example of ClassificationDataSet
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0],
test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample( training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1] )
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(net, dataset=training_data, momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(trainer.testOnClassData(dataset=test_data), test_data['class']))
Output of ClassificationDataSet
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')
Percent Error on testData: 3.34075723830735
If you have any queries regarding this article or if I have missed something on this topic, please feel free to add in the comment down below for the audience. See you guys in another article.
To know more about PyBrain Library Function please Wikipedia click here.
Stay Connected Stay Safe, Thank you

0 Comments