XgBoost library of Python was introduce at the University of Washington by scholars. It is a module of Python written in C++. XgBoost is stands for Extreme Gradient Boosting. XGBoost is an open-source software library. It is provides parallel tree boosting. It is design to help you build better models and works by combining decision trees and gradient boosting.
XGBoost Benefits and Attributes
- XGBoost is a highly portable library on OS X, Windows, and Linux platforms.
- XGBoost is open source and it is free to use.
- A large and growing list of data scientists globally.
- It is wide range of applications.
- This library was built from the ground up to be efficient, flexible, and portable.
Installation
pip install xgboost
Data Interface
This module is able to load data from many different types of data format.
- NumPy 2D array
- SciPy 2D sparse array
- Pandas data frame
- cuDF DataFrame
- datatable
- cupy 2D array
- Arrow table.
- XGBoost binary buffer file.
- dlpack
- Comma-separated values (CSV) file
- LIBSVM text format file
Objective Function
Training Loss + Regularization
A salient characteristic of objective functions is that they consist of two parts:
- Training loss
- Regularization
obj ( θ ) = L ( θ ) + Ω ( θ )
where, L is the training loss function, and Ω is the regularization term. A common choice of L is the mean squared error
Decision Tree
A Decision tree is a flowchart just like tree structure, where each internal node denotes a test on an attribute, each branch represents an outcome of the test, and each leaf node holds a class label is knows as Decision Tree.
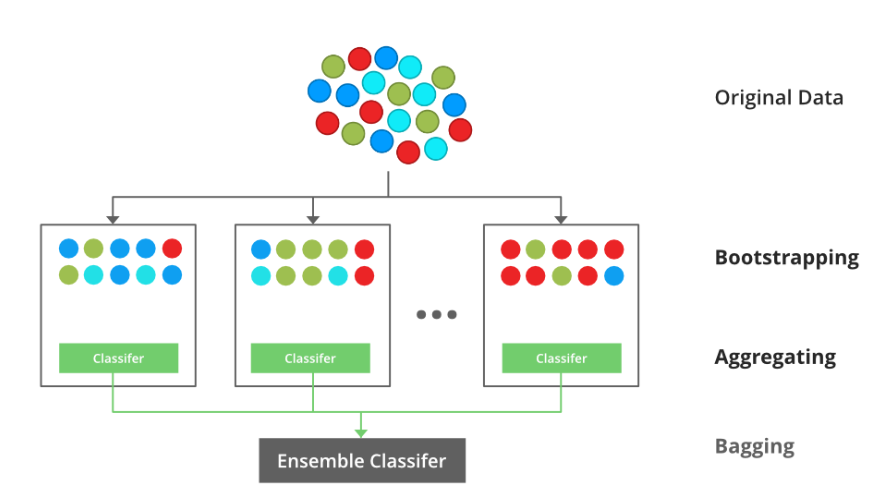
Bagging
A Bagging classifier is an ensemble meta-estimator that fits base classifiers each on random subsets of the original dataset and then aggregate their individual predictions to form a final prediction.
Mathematics behind XgBoost
Mathematics about Gradient Boosting, Here’s a simple example of a CART that classifies whether someone will like a hypothetical computer game X. Example of tree is below:
The prediction scores of each individual decision tree then sum up to get If you look at the example, an important fact is that the two trees try to complement each other. Mathematically, we can write our model in the form

where, K is the number of trees, f is the functional space of F, F is the set of possible CARTs. The objective function for the above model is given by

where, first term is the loss function and the second is the regularization parameter. Now, Instead of learning the tree all at once which makes the optimization harder, we apply the additive strategy, minimize the loss what we have learn and add a new tree which can be summarise below:

The objective function of the above model can be define as


Now, let’s apply taylor series expansion upto second order:

where, g_i and h_i can be defined as:

Simplifying and removing the constant

Now, we define the regularization term, but first we need to define the model

Here, w is the vector of scores on leaves of tree, q is the function assigning each data point to the corresponding leaf, and T is the number of leaves. The regularization term is then defined by

Now, our objective function becomes

Now, we simplify the above expression

Where,


Now, we try to measure how good the tree is, we can’t directly optimize the tree, we will try to optimize one level of the tree at a time. Specifically we try to split a leaf into two leaves, and the score it gains is

XGBoost
If you have any queries regarding this article or if I have missed something on this topic, please feel free to add in the comment down below for the audience. See you guys in another article.
To know more about XGBoost Library Function please Wikipedia click here.
Stay Connected Stay Safe, Thank you.

0 Comments